

How We Slashed Our Agent Costs by 25%, Without Touching a Single Line of Business Logic
.svg)
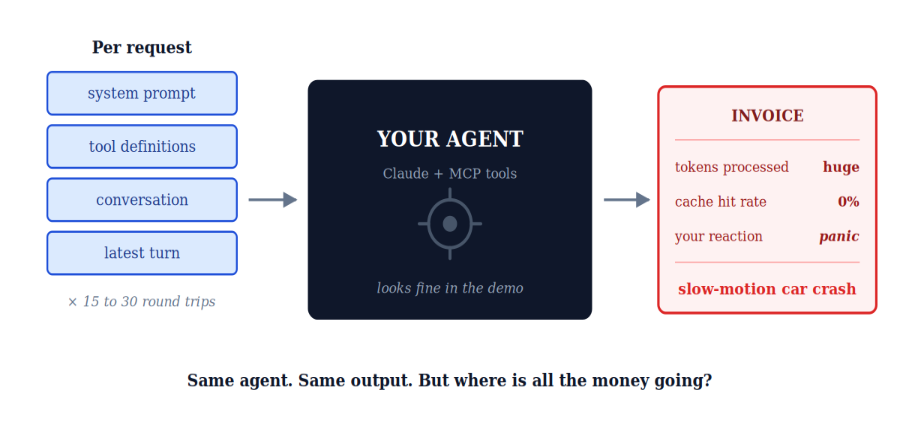
Building an AI agent looks deceptively simple in the demo. A system prompt, a handful of MCP tools, a model that thinks, and voilà, you have something that books meetings, queries databases, and writes reports.
Then the invoice arrives.
If you've ever shipped a real agent to production, you know the feeling. The unit economics in the README looked beautiful. The unit economics on the dashboard look like a slow-motion car crash. The model is the model. The tools are the tools. The prompts are the prompts. Where exactly is the fat to trim?
This is the story of how we cut our agent's per-iteration cost by 25% in production, on a live workload, with zero quality degradation and zero changes to the agent's behavior. The fix wasn't a smaller model. It wasn't fewer tools. It wasn't a clever prompt rewrite.
It was caching. Specifically, it was understanding why naive caching makes things worse, and then building the right caching topology around our agent loop.
Part 1: The Anatomy of an Agent Loop
Our agent runs on Claude Sonnet 4.6. It uses MCP (Model Context Protocol) servers on the backend to access tools, dozens of them, with rich JSON schemas. A typical report-generation task looks like this:
- The client sends a request.
- We assemble a prompt: a long, carefully engineered system prompt + the full set of MCP tool definitions + the user's task.
- Claude decides to call a tool.
- We execute the tool via MCP, append the result, and send the entire conversation back.
- Claude calls another tool. Goto step 3.
- Eventually Claude produces the final report.
A single report can mean 15 to 30 round trips to the model. And here's the thing that makes agent economics so brutal: in every one of those round trips, the system prompt and the tool definitions get re-sent. They never change. They're the same bytes, request after request. But the API doesn't know that. So it tokenizes them, embeds them, and runs them through the model's prefill stage every. single. time.

For our agent, the static prefix (system + tools) was the dominant cost driver. The actual conversation, the deltas that mattered, was a rounding error by comparison. We were paying full freight to re-process content that hadn't changed.
Key insight: In a long agent loop, the dominant cost is not what your agent is doing. It's the static prefix you keep re-tokenizing on every iteration. The bigger your tool catalog, the worse this gets.
Part 2: Sort Your Request by Volatility
Before we can cache anything intelligently, we need a mental model of what changes and what doesn't. Every agent request you send to Claude has exactly four strata, and they change at very different speeds.
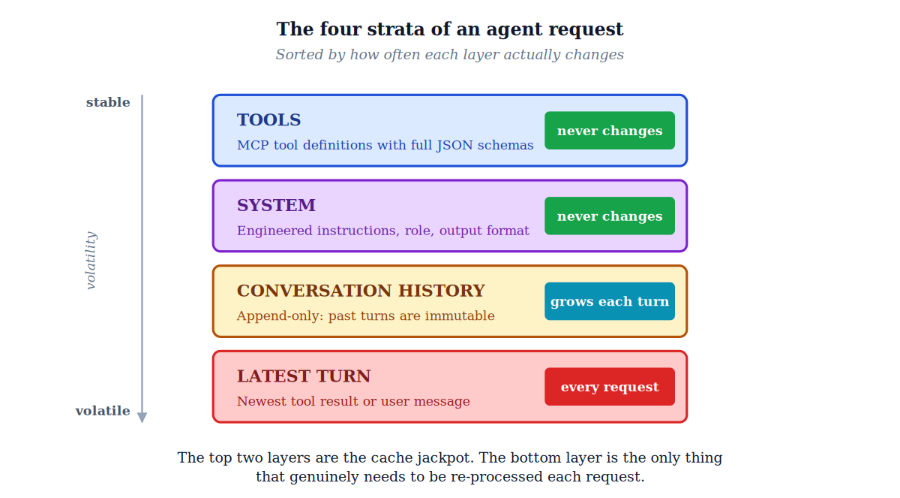
The top two layers are the cache jackpot. Tool definitions and the system prompt are identical across every single round trip in a session. The conversation history is monotonic: it only grows, never mutates. Only the bottom layer, the latest user message or tool result, is genuinely new content per request.
This volatility map is the foundation of everything that follows. The goal of any sensible caching strategy is to put cache breakpoints at the boundaries between these strata, not just anywhere.
Rule of thumb: Place cache breakpoints on the last block that stays identical across requests. Never on a block that changes every turn. That's a guaranteed cache miss.
Part 3: Why Automatic Caching Backfires
Anthropic's prompt caching is, on paper, exactly the cure for this disease. Mark a chunk of your prompt with a cache_control breakpoint, and on subsequent requests, the API reads that prefix from a KV cache instead of running it through prefill again. The economics are spectacular when it works:
- Cache write (first time): 1.25× the base input token price.
- Cache read (every subsequent hit): 0.10× the base input price, a 10× discount.
There are two ways to turn it on. Automatic caching: you drop a single cache_control field at the top level of your request, and the system magically places a breakpoint on the last cacheable block. As the conversation grows, the breakpoint moves forward automatically. It sounds perfect. Explicit cache breakpoints: you manually attach cache_control to up to four specific blocks in your request.
We started, like any reasonable team, with automatic caching. It's one line of code. The docs recommend it for multi-turn conversations. What could go wrong?
A lot, as it turns out.

Buried in the documentation is a detail that, if you skim past it, will quietly destroy your agent economics: the cache lookback window is 20 blocks.
When you fire a request, the system computes a hash of your prompt prefix at the breakpoint. If that exact hash isn't in the cache, it walks backwards, one block at a time, looking for a previous breakpoint that was cached. It will check at most 20 positions before giving up.
The gotcha: The lookback can only find entries that prior requests already wrote. It does not search for "stable content" behind your breakpoint. If you put the breakpoint on a block that changes every turn, you will get zero hits. Forever.
Part 4: The 20-Block Trap, Visualized
Picture our agent loop. Each iteration adds new blocks to the conversation: an assistant message with a tool call, a user message with the tool result, sometimes thinking blocks, sometimes long structured payloads. After about 7 to 10 tool-use iterations, you've blown past 20 new blocks since the last cache write.
With automatic caching, the breakpoint sits on the last block of the request, which is the freshly-appended tool result that didn't exist during the previous request. So the lookback starts there and walks backwards. After 20 hops, it's still not at the previous breakpoint. It gives up.

The system falls back to writing a fresh cache entry for the entire prefix, including the gigantic system prompt and the tool definitions we've cached a dozen times already. And cache writes, remember, are billed at a 25% markup over base input.
So when automatic caching missed on us (which it did, repeatedly, predictably, on every long-running iteration) we weren't just losing the discount. We were paying a premium to re-cache content we'd already cached. Every silent miss meant we were paying more than if we'd never enabled caching at all.
PM gotcha: For short tasks, automatic caching wins. For long agentic loops with many tool iterations, automatic caching can actively make your bill worse. And there is no error message warning you.
Part 5: The Four-Breakpoint Topology
Anthropic gives you a budget of four explicit cache breakpoints per request. That's the entire knob. Four. Not five. Not unlimited. Four.
So the question becomes: where do you spend them? We thought about this the way you'd think about CPU cache lines. What changes never, what changes rarely, and what changes every iteration? Map cost-by-volatility, then place breakpoints at the volatility boundaries.
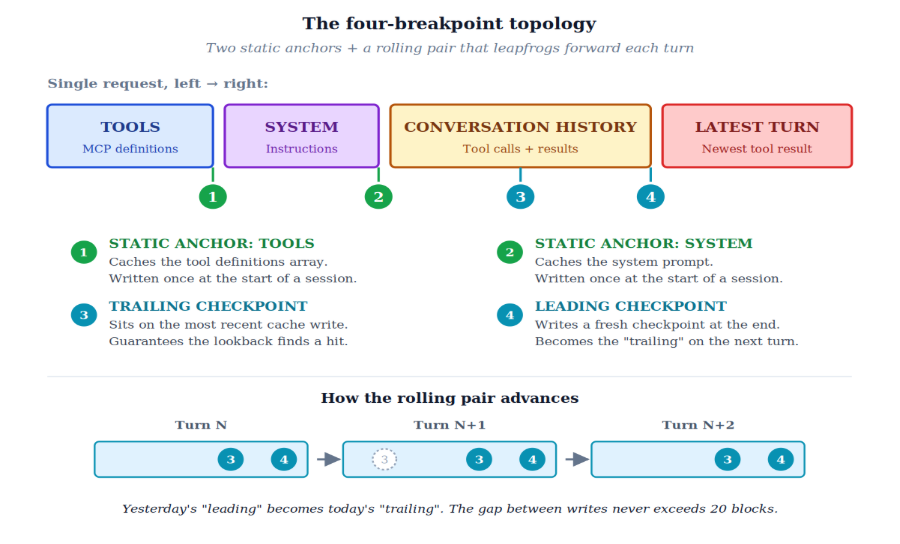
Breakpoint 1: Tools
Placed at the end of the tools array. Tool definitions are the most cacheable thing in the entire request: they're huge, they're identical across every iteration, and per Claude's cache hierarchy (tools → system → messages), they form the foundation of the prefix hash. This breakpoint pays for itself on the second request and prints money for the rest of the session.
Breakpoint 2: System Prompt
Placed at the end of the system block. Same logic, slightly less mass. Together with breakpoint 1, this locks in the entire static prefix.
Breakpoints 3 and 4: The Rolling Pair
This is where it gets clever. We don't place these statically. We roll them through the conversation as it grows, always positioned so that one of them sits comfortably inside the 20-block lookback window of the next request.
- Trailing breakpoint (3): sits at the most recent checkpoint we've written.
- Leading breakpoint (4): sits at the current end-of-history.
- On every request: leading becomes trailing, and we advance leading to the new end. Yesterday's leading is today's trailing.
It's a leapfrog. At any moment, we have two writes within reach: a recent one we can always read from, and a fresh one extending our cached reach. The 20-block window never traps us because we never let the gap grow that large.
The architecture in one line: Two anchors lock the static prefix. The rolling pair guarantees the next request always finds a recent write within the lookback window.
Part 6: The Math, in Relative Units
You don't need our dollar figures to follow the logic. The ratios in Anthropic's pricing tell the whole story. For any model that supports prompt caching:
- Base input tokens: the reference price, call it 1.0×.
- Cache write: 1.25× base.
- Cache read: 0.10× base, a 10× discount on every hit.
That 10× gap is the entire reason caching exists. Whether your prefix is 5,000 tokens or 50,000 tokens, whether you're on Sonnet, Haiku, or Opus, the multipliers are the same. Plug them into a 20-iteration agent run with a static tools+system prefix that we'd otherwise re-pay for on every turn:
Without caching: pay full price (1.0×) for the prefix, 20 times over → relative cost = 20.00 units.
With our four-breakpoint setup: one cache write at 1.25× plus nineteen cache reads at 0.10× = 3.15 units.
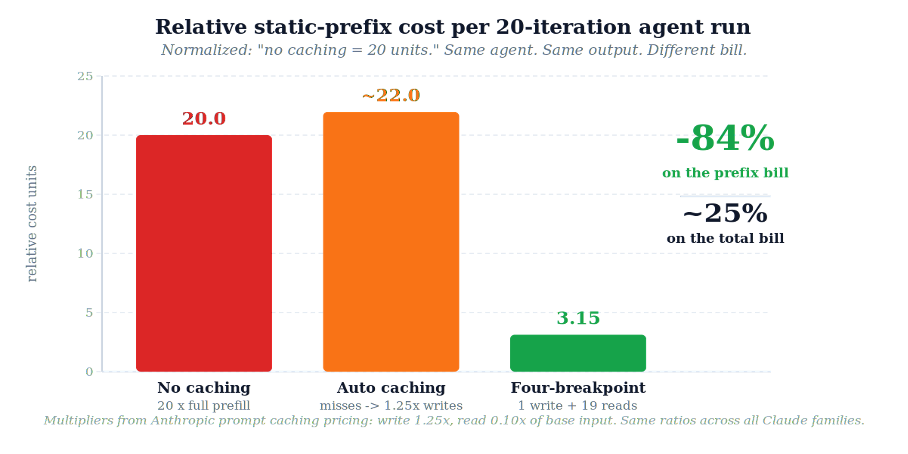
Now, the static prefix isn't the entire request. There's also conversation history, tool results, and the latest user/assistant turn, all of which scale differently. But the static prefix is by far the largest cacheable component, and once you fold the savings back into the full request, the realized reduction on our actual production traffic landed at a steady ~25% drop in total spend, week over week, with no degradation in output quality, no change in latency budget, and no architectural compromise.
We run several agents across different workloads, each with its own absolute cost profile, but the relative math holds across all of them. Twenty percent doesn't sound as sexy as eighty-four. But it's twenty percent of everything, on a workload that scales linearly with our customer base.
Key insight: Frontier models are getting cheaper per-token every quarter, but agents are getting more expensive because their token consumption is growing faster than the per-token price is falling. The loop is the cost. Compress the loop.
Part 7: Why This Is Harder Than It Looks
It would be nice to end here with a tidy "and so we turned on the feature and saved 25%." But the honest version is messier, and the messiness is the point.
Agent cost optimization is genuinely difficult because the failure modes are silent. When automatic caching falls back to a fresh write, the API doesn't warn you. It doesn't return an error. It doesn't even flag it as suboptimal. You only notice because your cost-per-iteration creeps up over time. And if you're not staring at the cache_creation_input_tokens and cache_read_input_tokens fields in every response, you'll never know it's happening.
To get this right, you have to:
- Understand the cache hierarchy. Tools cache invalidates system cache invalidates messages cache. Touch anything upstream and you blow away everything downstream.
- Understand the lookback window. Not just that it exists, but how it interacts with your iteration cadence.
- Instrument the cache. Every API response tells you how many tokens were read, written, or uncached. Log them. Watch them.
- Design the topology, don't inherit it. The default is wrong for agents. You have to think about volatility boundaries and place your breakpoints accordingly.
This is real systems engineering. It's the unglamorous middleware work that doesn't show up in keynote demos but absolutely shows up in margin reports.
The One Mental Model to Rule Them All
"The model is the model. The bill is negotiable, if you know where to spend your four breakpoints."
We didn't make our agent smarter. We didn't make it faster. We didn't even change what it does. We just stopped re-paying for the parts that never change. We did it by spending our four cache breakpoints on the right four blocks.
Twenty percent off the bill. Same agent. Same output. Same client.
If you're running an agent in production and you're still on automatic caching (or worse, no caching at all) you have an unforced error sitting in your codebase. Go fix it.
References
- Prompt caching: Claude API Docs: the canonical reference for everything covered in this post: pricing multipliers, the 20-block lookback window, the cache hierarchy, automatic vs explicit breakpoints, and the four-breakpoint budget.
- Automatic caching. What we tried first.





.svg)





.svg)