

Redesigning the Enterprise Interview for AI-Native Roles
A 90-day playbook for hiring in the AI-native enterprise. Five moves, the templates to run them, and the metrics to know whether they worked.
By filling up this form, you agree to allow Draup to share this data with our affiliates, subsidiaries and third parties


Understanding the Problem
Two days before this playbook went to press, Elon Musk posted a hiring notice for SpaceXAI that reads like a one-line referendum on how most enterprises hire. He asked for world-class engineers and physicists with zero prior AI experience required, described the right candidate in a single sentence, and asked applicants to send three bullet points of demonstrable achievement. He said he would read the qualifying ones himself.
Strip out the showmanship, and three claims remain that every CHRO should be ready to either defend or explain. AI domain experience is not a prerequisite for capable engineers. The right test is whether a candidate has made a complex thing do useful work, not whether they can solve a textbook puzzle on a whiteboard. The screening signal worth chasing is evidence of achievement, not a resume keyword match.
Most enterprise interview loops in 2026 disagree with all three. The data shows that disagreement is expensive.
Why the Interview Loop Is the Highest-Leverage Fix This Quarter
Of the six causes of AI impact lag inside enterprises, recruitment is the one talent leaders can actually change this quarter. Training programs take 18 months to compound. Skills architectures take 12 months to rebuild. The interview loop can be rewritten in 90 days, and the quality of every hire after that flows from it.
The problem is precise: most enterprises are still screening engineering candidates against a job description from 2015, inverting binary trees on whiteboards, while the actual job has moved to designing data pipelines between Workday and a data lake, defending against AI red teams, and orchestrating fleets of agents. The interview loop has not followed. The gap between what the loop measures and what the job rewards is now large enough to systematically filter out the best candidates.
What follows is a playbook built around that gap. The diagnostic case sits in the next section. The artifacts to act on are in the sections after that.
The Gap You Are Closing
Two charts define the problem precisely. The first shows where engineering time actually goes in 2026 compared to 2018. The second shows what the current interview measures versus what the job rewards. Both are based on Draup analysis of 200 or more technical interview loops conducted in 2026. The new loop is built around the gaps these charts surface.
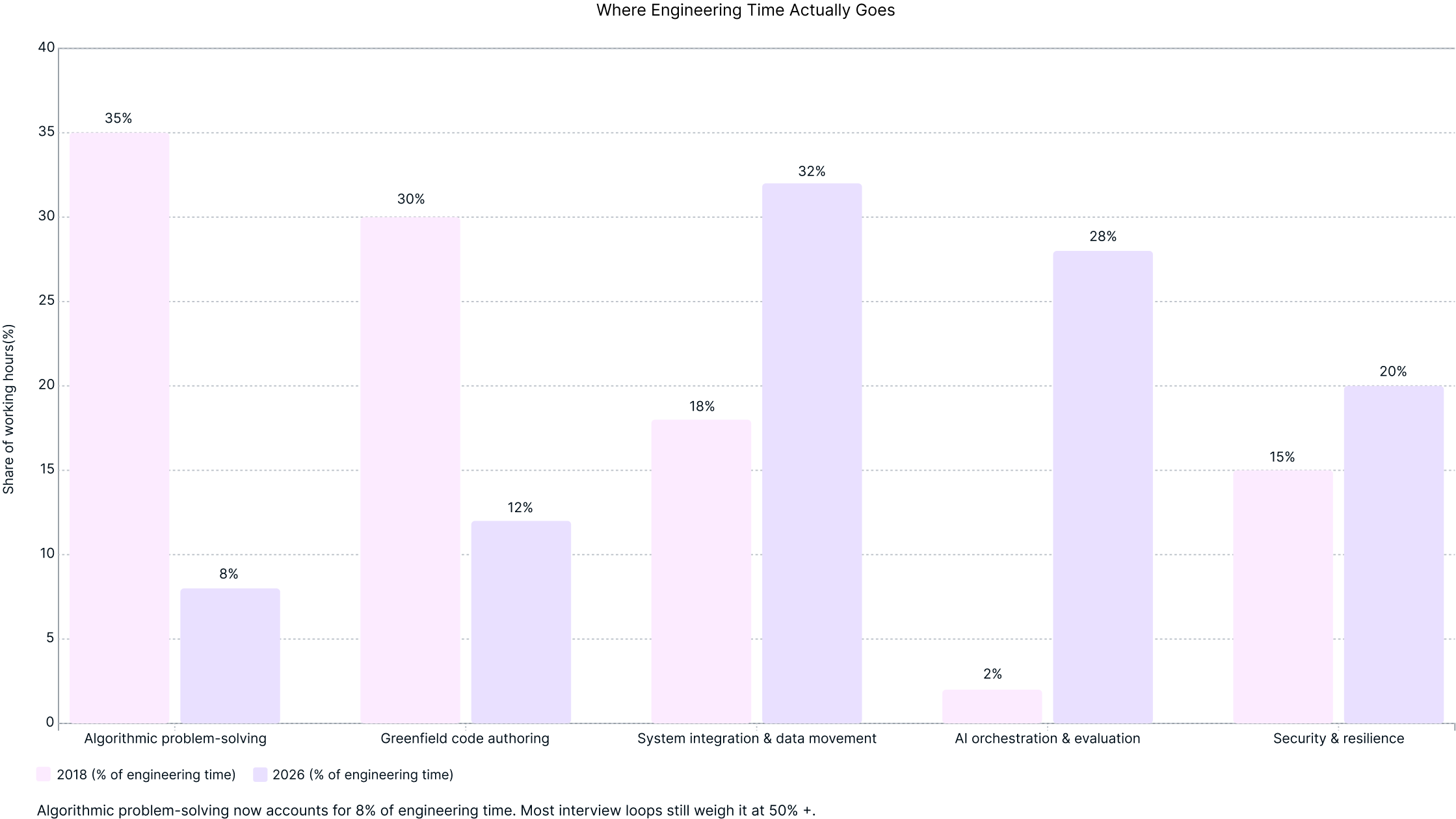
The shift is not subtle. Algorithmic problem-solving has fallen from 35% of engineering time in 2018 to 8% in 2026. System integration and data movement has grown from 18% to 32%. AI orchestration and evaluation has grown from 2% to 28%. The interview loop has not tracked this shift. It still allocates more than 50% of screening time to the task that now accounts for 8% of the actual job.
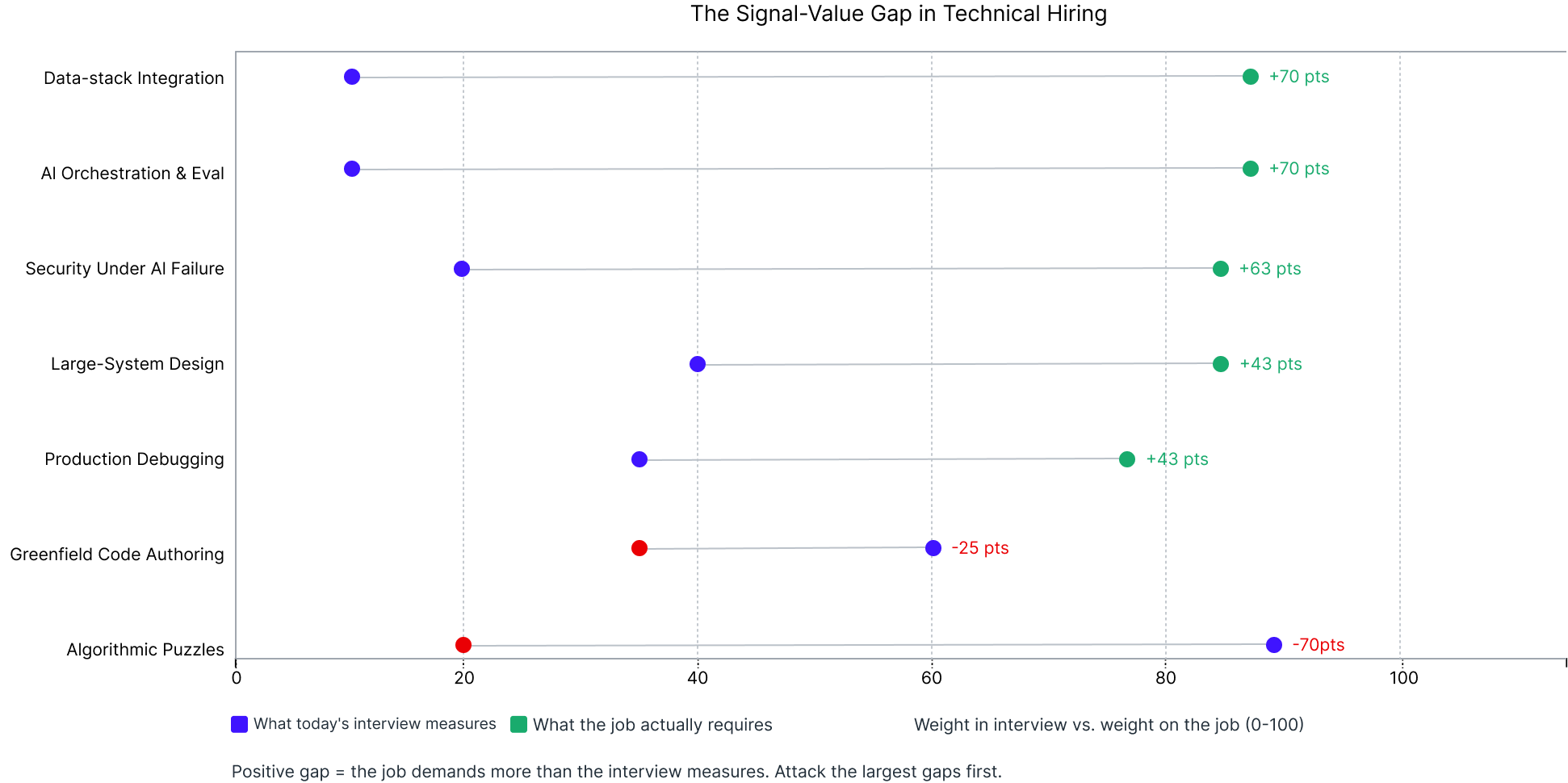
Read Figure 2 as a punch list. Data-stack integration and AI orchestration each carry a gap of 70 points. Security under AI failure carries 63 points. Large-system design and production debugging each carry 43 points. Algorithmic puzzles carry a gap of negative 70 points, meaning the interview overweights this skill by 70 points relative to what the job actually rewards. Reallocating the screening hour is most of the work.
The Five Moves
Pick all five. Do them in order. The sequence matters because each move builds on the one before it.
Pick Two Pilot Roles and Name Owners
The playbook starts with two roles, not a fleet-wide rollout. One engineering role and one non-engineering role. The reason for two is that the failure mode on the non-engineering side is distinct from the engineering side, and the rubric needs to reflect that. Each role needs a named individual owner, not a team or a committee. The owner is accountable for the artifact shipping by the deadline. Names on the wall, not titles.
What this produces:
Two sandboxed exercises, one for each role, with named owners responsible for their delivery within the first 35 days.
Replace the Algorithmic Round With a Live Systems Exercise
The algorithmic round tests a skill that accounts for 8% of the actual job. Replace it with a 90-minute live exercise in which the candidate has access to an integrated development environment, the AI assistant of their choice, and a sandboxed copy of two real systems. The exercise tests what the job actually requires: system decomposition, data contract design, AI failure thinking, security posture, use of the agent, and communication.
Sample engineering prompt (verbatim from playbook):
You are joining the platform team. Workday is our HRIS. We need a daily feed of employee data into our Snowflake-backed data lake, where downstream HR analytics jobs read it. Constraints: PII must be encrypted in transit and at rest. The job must be idempotent. Late-arriving records must reconcile. The downstream team is non-technical and needs a contract.
Twist (announced at minute 45): The Workday schema just changed. One column was renamed, one was added. Show how your design detects, surfaces, and routes this without a 3 a.m. page.
You can use the AI assistant freely. We will judge how you drive it as much as the code itself.
The scoring rubric covers six dimensions for a total of 100 points. The visual below shows each dimension, its weight, and what a strong answer looks like.
New Engineering Interview Scoring Rubric

Green flags and red flags to share with every interviewer

Rewrite the Senior Rubric for AI-Failure Thinking
The senior rubric in most enterprise loops rewards depth of craft knowledge and breadth of architectural experience. Neither criterion asks how the candidate thinks about AI failure modes. That omission now matters: senior engineers are increasingly responsible for systems where a model hallucination, a rate-limit breach, or a schema drift event can cause a production incident at 3 a.m. The rubric should reflect that.
Rewrite the senior rubric so that AI-failure thinking is an explicit dimension. A candidate who cannot name at least three failure modes in an AI-assisted workflow and design an escalation path for each is not senior by the standards the job now requires.
What to add to the senior rubric:
- Can the candidate identify hallucination, rate-limit failure, and schema drift as distinct failure classes?
- Do they design an escalation path for each, or treat failure as a single undifferentiated event?
- Do they know when to override the model and how to document that decision for an audit trail?
Reset Sourcing Weights Toward Portfolio Depth and Adjacent-Industry Experience
The current sourcing model in most enterprises weights school name and prior employer brand heavily. Both are proxies for capability that have weakened significantly as the actual job has shifted. A candidate who built a data pipeline between two enterprise systems in a different industry has more relevant experience for the role than a candidate who graduated from a top school and spent three years inverting binary trees at a well-known technology firm.
Reset sourcing weights toward portfolio depth, specifically evidence of having made a complex system do useful work, and adjacent-industry experience, specifically candidates who have operated in environments where the integration and orchestration challenges are similar even if the domain is different. Both signals predict job performance better than school or prior employer brand under the current job shape.
Run the New Loop in Parallel With the Old One for 60 Days
Do not retire the old loop immediately. Run both in parallel for 60 days on the two pilot roles. This produces a comparison dataset: which loop surfaces candidates who perform better in the first 90 days on the job, who passes the old loop and fails the new one, and who passes the new loop and would have been filtered out by the old one. That comparison is the evidence base for negotiating a broader rollout. Without it, the conversation with hiring managers is philosophical. With it, the conversation is about data.
The Non-Engineering Variant
The same principle applies to non-engineering roles in Finance, Operations, HR, and Customer Service. Bring an agent into the room. Watch how the candidate uses it, verifies it, and explains when not to trust it. The domain changes. The screening logic does not.
Sample prompt for a Finance analyst role (verbatim from playbook):
Here is a folder of 18 vendor invoices and a copy of our procurement policy. Use any AI tool you like. In 45 minutes, please provide a list of invoices to flag for review, along with the reasons. Then walk me through one invoice where the AI tool told you something wrong, and explain how you caught it. If you cannot find one where the tool was wrong, walk me through how you would design a spot-check for next month.
What the non-engineering loop is screening for:
- Can the candidate decompose an ambiguous business question into a usable AI prompt?
- Do they verify the AI output against a known reference before acting on it?
- Can they articulate when human judgment must stay in the loop?
- Do they communicate trade-offs in plain language to a business stakeholder?
- Do they recognize their own bias and the AI bias as separate problems?
The 90-Day Delivery Timeline
The tracker below shows how the five moves sequence across 90 days. Tasks overlap deliberately: the systems exercise is built while the audit is still running, so that audit findings can be incorporated into the exercise design before it is finalized. The Gantt is not aspirational. Each bar represents one named owner and one shipped artifact.
Monday morning checklist to start this week:
- Pull the last 100 interview loops. Score them against the six capabilities in the rubric above.
- Name two pilot roles and two owners. Put names, not titles, on the wall.
- Pick one real Workday-to-data-lake integration in your stack. Sandbox it for the exercise.
- Identify ten interviewers, half engineering and half hiring managers from the line of business.
- Book the kickoff. The exercise prompt and rubric in this playbook are ready to copy.
How Draup Supports Recruitment Transformation
Draup provides the talent intelligence that makes the five moves faster and more defensible. We analyze 25M or more data points daily from 75,000 or more sources, including Fortune 500 job postings, compensation benchmarks, skills demand signals, and real-time shifts in what enterprises are actually hiring for versus what their job descriptions still say.
For CHROs and Talent Acquisition Leaders:
Draup surfaces what skills Fortune 500 firms in your sector are actually screening for in 2026, at the job-posting level, so your rubric reflects the market that exists rather than the market that existed five years ago.
Identify which capabilities are growing fastest in your target engineering roles and which are declining, giving the sourcing reset in Move 4 a data foundation rather than a hypothesis.
Map where the candidates with the right portfolio depth and adjacent-industry experience actually sit, by geography, employer, and career trajectory, before sourcing begins.
Understand the pay premium the market is attaching to AI-fluency skills in your target roles so that offer competitiveness keeps pace with the upgraded hiring bar.
Implications for Talent Leaders
The five moves in this playbook are sequenced so that each one compounds the one before it. Running them out of order, or picking two of five, produces a partial fix that leaves the biggest gaps intact. The implications for how talent leaders should think about this quarter
Training and skills architecture changes take 12 to 18 months to compound. The interview loop can change in 90 days and begins improving hire quality immediately.
A 70-point gap on data-stack integration and AI orchestration is not a calibration error. It reflects an interview design that has not tracked the job for at least four years.
The comparison dataset it produces is the only thing that converts a philosophical argument about interview design into a data-backed case for broader rollout.
Score your own loop honestly before picking pilot roles. Most enterprises will land mostly red. That is the starting point and the punch list.
What can this candidate do with an agent next to them?
Methodology: How We Derived These Insights
Primary Research Basis
- This playbook grew from a session on AI architecture delivered at the Strategic Workforce Planning conference in Chicago in May 2026.
- Engineering time allocation data (Figure 1) is drawn from Draup analysis of a typical platform-engineering role, 2026. The chart is labeled illustrative in the source PDF.
- Signal-value gap data (Figure 2) is drawn from Draup analysis of 200 or more technical interview loops, 2026.
- All rubric dimensions and weights, green and red flag lists, sample prompts, and 90-day tracker dates are stated verbatim in the source PDF.
Scope and Caveats
- The engineering time allocation data reflects a typical platform-engineering role and should not be generalized to all engineering functions without validation against the specific role in question.
- The signal-value gap figures represent gaps across 200 or more interview loops analyzed. They are directional indicators, not universal benchmarks.
- The 90-day timeline assumes a single business unit pilot. Enterprise-wide rollouts will require longer timelines.
Note: This page is structured as a decision guide for HR and talent acquisition leaders evaluating recruitment transformation strategies. It does not represent hiring advice for specific organizations or roles.



.svg)





.svg)