

Data is being generated at a massive rate across all the businesses. When the data volumes are large, we would want to look at the subsets(apply filters) of data that might be of interest to us. So traditionally these filters translate to database queries. A simple query for all profiles in IBM would look like
SELECT * from profiles where company = “IBM”
Draup faces a very similar challenge when it comes to presenting its data to users in a meaningful manner. It has a large ecosystem of profiles which the users can narrow down based on several filter parameters. You can select profiles based on company, location, skills, business function and a few more.
Here is what the filter based approach looks like.
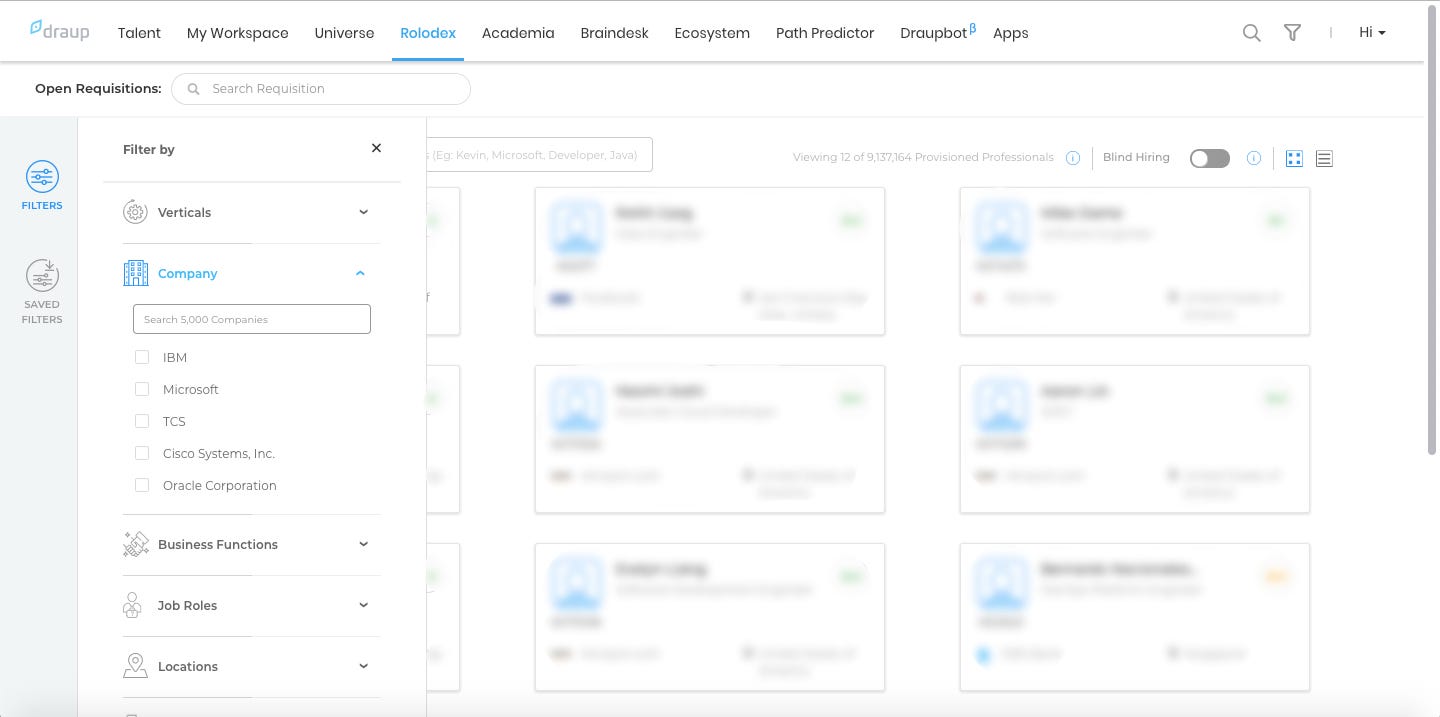
When each category has only a few options, filtering is easy but as the options for each category increases, then the complexity blows out of proportions.
An alternative approach for querying
At Draup we wanted to do away with this way of filtering the search results and improve our user experience. So we worked on an alternative way of querying the platform. The users can now enter free text queries and say goodbye to all the clutter created by filters. Here are a few examples:-
- Show me data engineers skilled in python - Someone who is located at san francisco with the qualification of a data scientist. - Show me top executives in Amazon - Adam from Microsoft, Redmond
So the first query should translate to the following SQL query.
SELECT * from profiles where JOB_TITLE = “data engineer” and SKILL = “python”
We approached this problem from a machine learning viewpoint. This problem is known as Named Entity Recognition(NER) in the ML world.
Building a Named Entity Recognition System
Named entity recognition is a subtask of information extraction that seeks to locate and classify named entity mentions in unstructured text into pre-defined categories such as the person and organization names, locations, dates, etc.
There are brilliant open-source models (1, 2, 3, 4)for NER but they are very generic in nature. These models work well with general entity types like person names, locations, organizations, dates, etc, but at Draup we are concerned with much more. We have several other entities like skills, sub-verticals, business functions, level in organization, etc, which cannot be covered by these pre-trained models. So we came to the conclusion that we have to build our own NER system.
Building the dataset
This is usually the most crucial part of any Machine Learning (ML) process. ML follows a simple rule, “garbage in, garbage out”. This means that an ML model is only as good as the data it is trained on. Keeping this in mind we worked on generating as many examples as possible. We could reach to about 200 possible queries. This is a relatively small dataset for training a model. A careful study of user querying patterns gave us ideas about how to generate more data by data augmentation. People seem to not care about properly capitalizing important words in a free text query. A lot of the users pay no attention to using proper punctuations but still expect models to work. These insights help us build a quick data augmentation pipeline to create more training examples for us. All these efforts resulted in a total of 1000 training examples.
Choice of Modelling Technique
There are two major themes for building a NER system:-
- Traditional algorithms like conditional random fields (CRF)
- Deep learning based approaches
Deep learning based approaches in the realm of text data work really well if you have a large dataset. About 1000 example doesn’t cut the bar. More recently, general language models like Google’s BERT or OpenAI’s GPT-2 have shown promising results on smaller datasets. However, these models are huge in size and we felt that they are a bit of an overkill for our task. Another important drawback of deep learning when compared to traditional approaches is that it’s difficult to interpret and explain model behavior.
Conditional random fields, on the other hand, works quite well on NER task even when the data is limited.
Conditional Random Fields Model
This section talks about CRF in some intuitive detail but has some mathematics involved. You can choose to skip it.
A conditional random fields model is used when we are working with sequences. In our case, the input is a sequence of words and the output is a sequence of entity tags.

Let’s call the word sequence as x̄ and the tag sequence as y̅.
Also, let’s define what we call as feature functions: f(yᵢ₋₁, yᵢ, x̅, i)
Here the feature function takes 4 parameters:-
1: i, the current index in the sequence
2: x̄, the entire input sequence
3: yᵢ₋₁, the previous output tag indexed on i
4: yᵢ, the current output tag indexed on i
To make thing more clear, let’s define a sample feature function.
f(yᵢ₋₁, yᵢ, x̅, i) = { 1 if both yᵢ₋₁ & yᵢ are TITLE and the current word is ‘Engineers’, else 0}
As you can see, this is quite a descriptive feature function and if we define a lot of such feature functions we extract a lot of information about our text data. Here is another feature function.
f(yᵢ₋₁, yᵢ, x̅, i) = { 1 if yᵢ₋₁ is OTHER, yᵢ is TITLE and the current word is capital cased, else 0}
After collecting a bunch of feature functions we want to find a probability distribution function. This function should tell what is the probability of every possible y̅ given x̅. Below equation defines this probability.
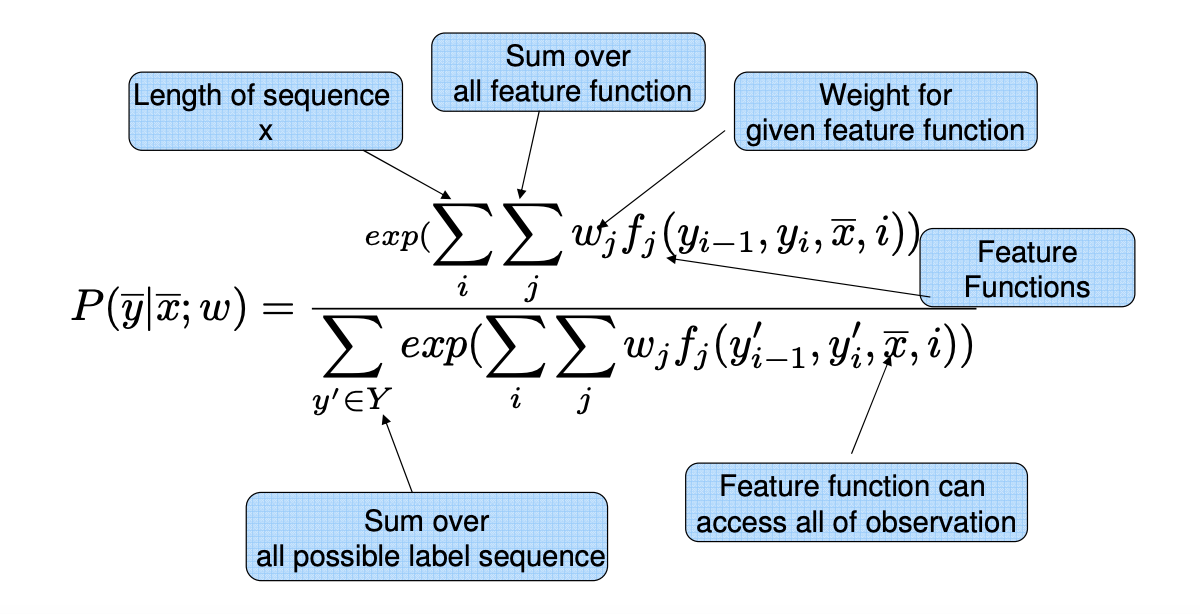
Here exp is the exponential function. The above function uses exponentials to smoothly distribute the probability across all possible label sequences and ensures that the sum of probabilities is 1.
If you notice carefully, you will see that each feature function is given a weight, which makes sense intuitively as not all feature functions carry equal importance. Now, given the data, we want to maximize the conditional likelihood of our data and find the best set of weights.
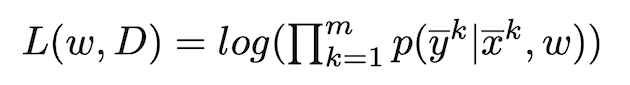
Here L is the conditional likelihood function and k iterates through all the training examples. Using gradient descent we can learn the most suitable parameters (weights) for our dataset.
Well, that seems like a lot of work but we used the sklearn-crfsuite library to train the CRF model on our dataset of approximately 1000 examples.
Precision, Recall and F1 Score
Let’s explain precision and recall with a simple example. Suppose we build a model that can predict/extract all the skills mentioned in a text. Suppose our input text has 9 skills. Let’s say that the model predicts 10 skill, out of which 6 are actually skills and the other 4 are not skills.
A = Number of relevant records = 9
B = Number of relevant records retrieved = 6
C = Number of records retrieved = 10
D = Number of irrelevant records retrieved = 10–6 = 4
Precision = B/C = 0.6
Recall =B/A = 0.667
A good model will have high values for both precision and recall. However, sometimes it is good to have a single value to give an estimate of how good the model is. Thus comes f1-score. It combines both precision and recall harmonically.

So in our example, the f1 score is 0.632
Model Validation and Improvements
It is somewhat okay if the model doesn’t recognize all the entities in a query. But if the model identifies entities incorrectly, then the results are impacted harshly. For example, if the model identifies a person name as a skill, then highly likely there will be no search results. Thus we want a very good precision and as much recall as possible.
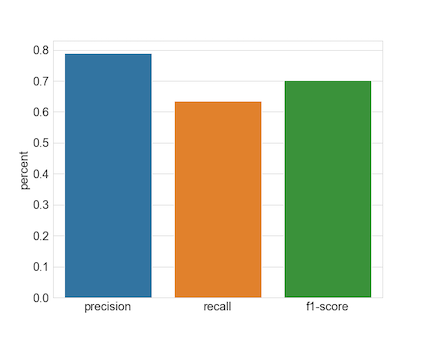
Our initial efforts lead us to the following results.
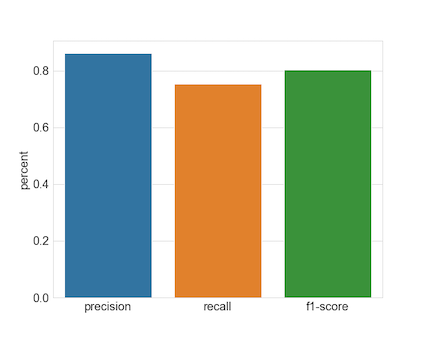
Precision: 0.790
Recall: 0.635
F1-score: 0.702
These results are on completely unseen data.
If you look at the recall, it seems quite less. And this seems to be a problem with CRF technique. CRF usually achieves good precision but lack in recall.
To solve the problem of low recall we introduced a few feature functions that use our curated lists of several entities.
f(yᵢ₋₁ , yᵢ, x̅, i) = {1 if yᵢ₋₁ is OTHER, yᵢ is SKILL and the current word is present in our list of known skills, else 0}
Let’s say that our list has skills like:-
(‘AutoCAD’, ‘python’, ‘java’, ‘MongoDB’, ‘nodejs’, ……)

After defining such features for a few other entities we achieved great improvement. A Model built just after introducing these features gives the following results.
One other trick that helps our engine to perform well in production is the use of Spell Correction. Users seem to be in a hurry when they make queries to the system. We often encounter queries like:-
Show me managers in amazon
java developers in london
A spell correction process helps us largely rectify such cases and make our system more usable.
What does it look like
The system now allows users to input a free text query, then extracts and shows the entities to the user as well as shows results based on these entities/filters.
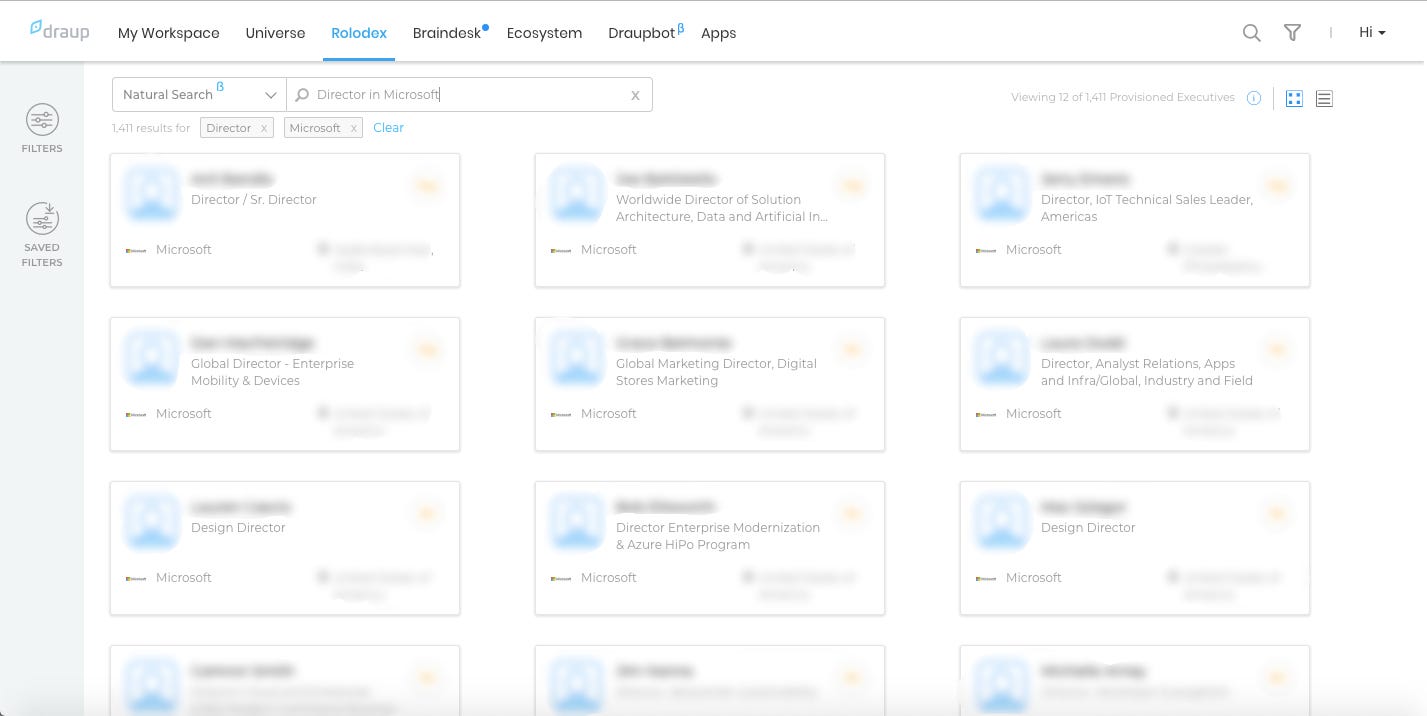
The above example shows the query “Director in Microsoft”. The system correctly identifies the entities Director and Microsoft and applies these filters for you.
This is just the beginning of the free text query engine. Our system will improve as we get more data to train.
tl;dr This article talks about how we introduced a free text query engine to replace a traditional filter based approach for querying data using named entity recognition and some other tricks.



